闭包
知识引入:
为什么外部无法调用内部函数的变量定义,怎么才可以调用内部函数
function fn() { let count = 0; console.log(`函数被调用了${count}次`); return "调用完成";}fn();console.log(count); //ReferenceError: count is not defined代码执行前:创建执行上下文、分配内存地址
- 全局执行上下文(Global Execution Context 被创建。
- 在全局作用域中,引擎会声明
fn函数,并为其分配内存地址。此时,fn是一个指向其函数体的引用。 count变量还未被创建,因为它在fn函数内部。
代码执行阶段:作用域链查找、执行函数
fn()被调用。JavaScript 引擎会在调用栈(Call Stack)上创建一个新的函数执行上下文(Function Execution Context)。- 创建
fn的作用域:每个函数执行上下文都有自己的作用域。当fn的执行上下文被创建时,它会创建一个私有作用域。 - 声明并初始化
count:在fn的私有作用域中,let count = 0;这行代码执行。引擎在这个私有作用域内分配一块内存,并将其命名为count,值为0。 - 执行
console.log:console.log(函数被调用了 ${count} 次);执行。引擎需要查找count的值。它首先在fn的当前作用域中查找,成功找到count,其值为0。因此,控制台输出函数被调用了0次。 - 函数执行完毕:
return "调用完成";执行,函数执行上下文完成使命。
函数执行后:垃圾回收机制
- 弹出调用栈:
fn的执行上下文从调用栈中弹出。 - 销毁私有作用域:由于
fn函数已经执行完毕,并且没有任何外部引用指向其内部的变量(闭包情况除外),JavaScript 的垃圾回收器会认为fn的私有作用域及其内部的所有变量(包括count)都是 “无用内存”。 - 回收内存:垃圾回收器会在未来的某个时间点,回收
fn私有作用域所占用的内存,count变量也就随之被销毁了。
基础知识
1.内存
我们来想象一下计算机的内存。我们可以把它看作一张巨大的、有边界的网,这张网由无数个小格子组成。
“在现代计算机中,我们通常把每一个小格子称为一个字节(Byte)。这是内存的最小操作单位。每个格子都有一个唯一的编号,我们称之为内存地址。当我们说‘把数据存入内存’时,本质上就是把数据转换成二进制的 0 和 1,然后放进这些格子里,并记住它们的地址,以便后续查找。”
内存存储的3个核心规律
- 所有数据最终都是二进制:无论数字、文字、图片、代码,必须先转成0和1的组合,才能存进格子。
- 格子按需分配,不够就拼:1个格子(1字节)存不下的,就用2个、4个、8个…连续格子(比如中文用3字节,大整数用8字节)。
- 每个格子有唯一地址:CPU找数据时,不是“找内容”,而是“找地址”——比如要改
count的值,先通过变量count拿到它的内存地址,再去对应格子里改二进制。
理解了内存的基本模型后,我们来看看不同类型的数据是怎么”安家“的。JavaScript 的数据类型分为两大类:简单数据类型(如 Number, String, Boolean, null, undefined, Symbol)和复杂数据类型(主要是 Object,包括 Array, Function 等)。
它们的‘家’是不同的。简单数据类型因为体积小、大小固定,所以直接住在离 CPU 最近、速度最快的栈内存 (Stack) 里。变量名和它的值是‘绑定’在一起的。
而复杂数据类型,比如一个对象或数组,因为体积可能很大且大小不固定,所以它们被安排住在更宽敞的堆内存 (Heap) 里。这时,栈内存里的变量名不再直接存值,而是存一个 门牌号—— 也就是指向堆内存中实际数据的引用地址
2.数据类型
简单记:基本类型传值,引用类型传址,这是JS中调用和赋值行为的核心逻辑。
堆栈空间分配区别:
1、栈(操作系统):由操作系统自动分配释放存放函数的参数值、局部变量的值等。其操作方式类似于数据结构中的栈;简单数据类型存放在栈里面
2、堆(操作系统):存储复杂类型(对象),一般由程序员分配释放,若程序员不释放,由垃圾回收机制回收;复杂数据类型存放到堆里面
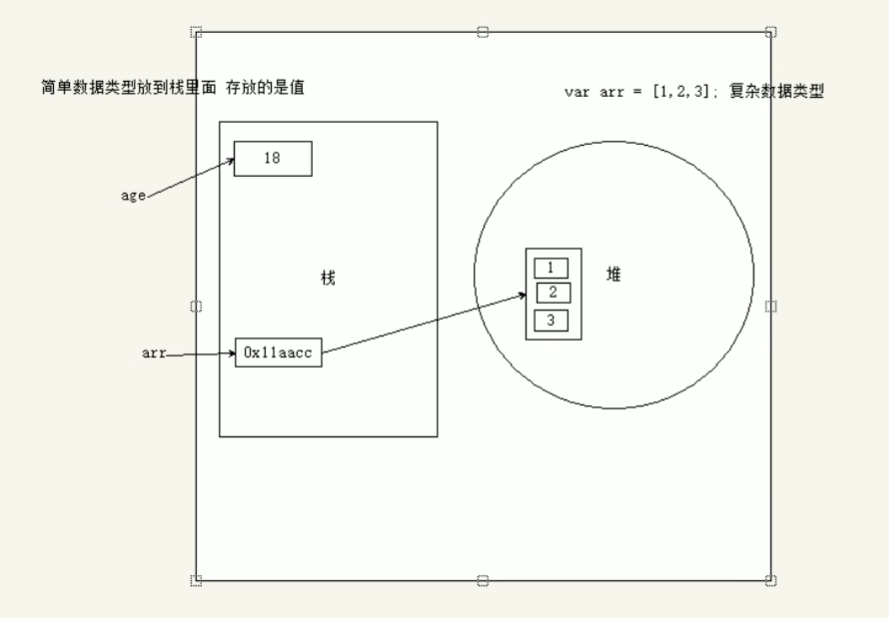
- 简单数据类型 是存放在栈里面,里面直接开辟一个工作空间存放值
- 复杂数据类型 首先在栈里面存放地址,十六进制表示,然后这个地址指向堆里面的数据
基本数据类型传参
函数的形参可以看作是一个变量,当我们把一个值类型变量作为参数传给函数的形参时,其实就是把变量在栈空间里的值复制了一份给行参,那么在方法内部对形参做任何修改,都不会影响到的外部变量
function fn(a) { a++; console.log(a);}var num = 20;var x = 10;fn(x);console.log(x); 
引用数据类型传参
函数的形参也可以看作是一个变量,当我们把引用类型变量传给形参时,其实是把变量在栈空间里保存的堆地址复制给了形参,形参和实参其实保存的是同一个地址,所有操作的是同一个对象。
function Person(name) { this.name = name;}function f1(x) { console.log(x.name); x.name = "张学友"; console.log(x.name);}var p = new Person("刘得花");console.log(p.name); //f1(p);console.log(p.name);
难道数据是一直存在的吗?这种‘简单类型住栈,复杂类型住堆’的设计,直接决定了它们的‘生命周期’是如何被管理的。这就引出了我们的下一个话题 —— 垃圾回收。
想象一下,如果我们只向内存中存数据而从不清理,内存很快就会被占满,程序就会崩溃。好在 JavaScript 引擎自带了一位‘自动清洁工’,叫做垃圾回收器 (Garbage Collector, GC)。它的工作就是找出那些‘再也用不到’的内存,并把它们回收掉,以便腾出空间。”
那么,GC 如何判断一块内存是否‘再也用不到’呢?主要有两种策略:引用计数和标记 - 清除。目前主流的是‘标记 - 清除’算法。”
“它的核心思想是可达性 (Reachability)。简单来说,就是从全局的‘根’对象(比如浏览器环境下的window)开始,遍历所有能访问到的对象,给它们打上‘存活’的标记。遍历结束后,所有没有被标记的对象,就被认为是‘垃圾’,会被回收。”
“一个典型的例子是函数执行。当一个函数执行时,会创建一个执行上下文,它像一个临时的‘工作台’,存放着函数的参数和局部变量。这个‘工作台’就在栈内存里。当函数执行完毕后,这个‘工作台’就没用了,它以及上面的局部变量就会被销毁,内存被回收。”
3.JS中的垃圾回收机制
内存的生命周期JS环境中分配的内存,一般有如下生命周期:
- 内存分配:当我们声明变量、函数、对象的时候,系统会自动为他们分配内存
- 内存使用:即读写内存,也就是使用变量、函数等
- 内存回收:使用完毕,由垃圾回收器自动回收不再使用的内存
说明:
- 全局变量一般不会回收(关闭页面回收)
- 一般情况下局部变量的值,不用了,会被自动回收掉
内存泄漏:程序中分配的内存由于某种原因程序未释放或无法释放叫做内存泄漏
| 内存区域 | 主要存储内容 | 回收方式 | 回收时机 |
|---|---|---|---|
| 栈内存 | 基本类型、函数执行上下文 | 自动回收 (由执行栈管理) | 函数执行结束时 |
| 堆内存 | 引用类型 (对象、数组等) | 垃圾回收器 | 不确定,当对象变为不可达时 |
因此,当人们谈论 JavaScript 的垃圾回收机制时,他们几乎总是在讨论堆内存的回收。
JS的垃圾回收算法:
JavaScript的垃圾回收机制是浏览器或JS引擎自动管理内存的机制,核心目的是识别并回收不再使用的内存,避免内存泄漏和过度占用。其核心原理是自动跟踪变量的引用状态,当变量不再被引用时,标记为垃圾并释放内存。
常见的垃圾回收算法:
引用计数法(早期算法)
原理:跟踪每个值被引用的次数。当声明变量并赋值时,引用计数+1;当变量不再指向该值(如重新赋值、离开作用域),引用计数-1;当引用计数变为0时,标记为垃圾并回收。
缺点:无法解决循环引用问题(如两个对象互相引用,即使都不再被外部使用,引用计数也不会为0,导致内存无法回收)。
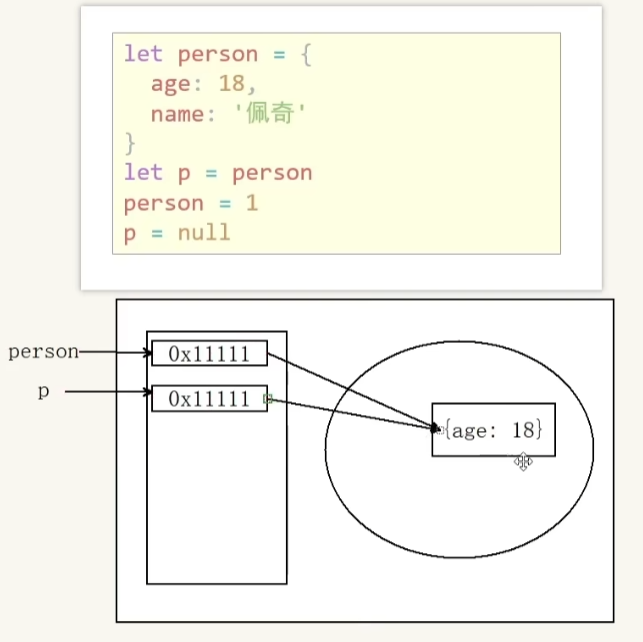
引用计数为2

引用次数为0,age<18未被使用>,清除
标记-清除法(现代浏览器主流算法)
原理:
标记阶段:从全局对象(如window)出发,遍历所有可达的变量(被引用的变量),标记为“活动对象”。
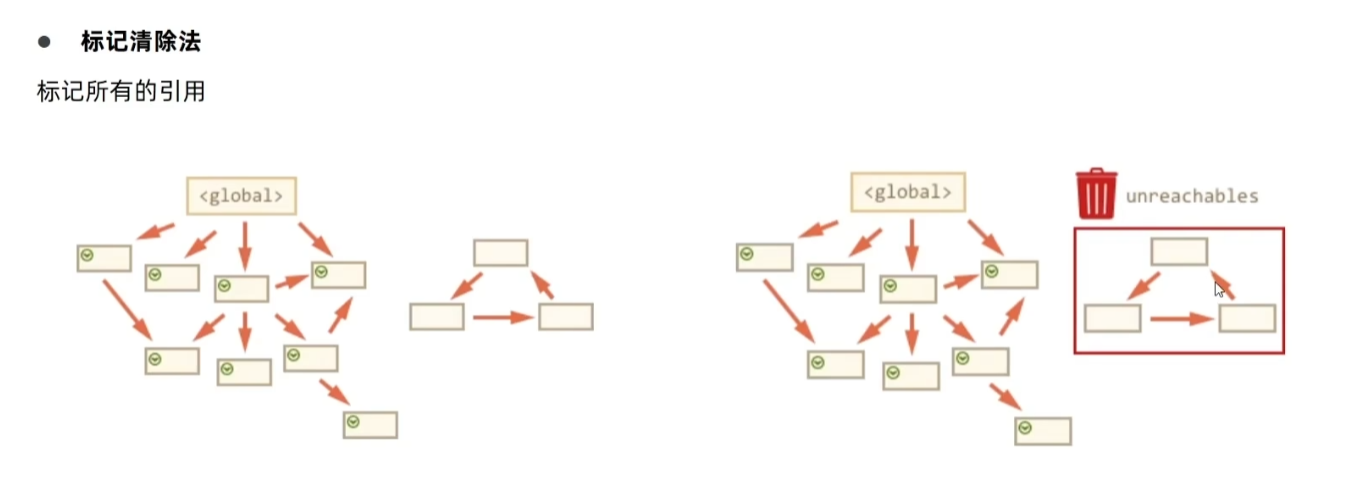
清除阶段:未被标记的变量(不可达,即不再被使用)被视为垃圾,释放其占用的内存。
优点:解决了循环引用问题,是目前大多数浏览器(如Chrome、Firefox)的主要垃圾回收算法。
如下:根部访问不到,自动清除

缺点:局部变量内部,函数相互引用无法被清空
分代回收(优化策略)(了解)
原理:根据变量的生存周期将内存分为“新生代”(短期存在的变量,如局部变量)和“老年代”(长期存在的变量,如全局变量),对不同代际采用不同的回收策略:
- 新生代:回收频繁,采用高效的“复制算法”(将活动对象复制到新空间,释放旧空间)。
- 老年代:回收频率低,采用“标记-清除”或“标记-整理”(清除后压缩内存碎片)算法。
- 垃圾回收的触发时机:
由JS引擎自动触发,通常在内存占用达到一定阈值、函数执行完毕(局部变量出作用域)或浏览器空闲时执行。
开发者无法直接调用垃圾回收,但可以通过合理编写代码(如及时解除引用)帮助引擎高效回收内存。
避免内存泄漏的常见场景:
- 意外的全局变量(未声明的变量会挂载到window,成为全局变量,长期不回收)。
- 定时器/事件监听器未及时清除(如setInterval引用的函数未销毁,导致关联变量无法回收)。
- 循环引用(虽然现代引擎可处理,但复杂场景仍可能导致泄漏)。
- DOM元素移除后仍被JS变量引用(DOM节点已从页面删除,但内存中仍被引用)。
为什么函数是从上往下执行的?为什么函数外访问不到函数内部的变量?
4.执行上下文和作用域链
执行上下文通俗的讲就是代码执行所处的当前容器
作用域链决定了代码的访问机制
执行上下文
简单引入:执行上下文(也称上下文)是当前代码的执行环境。(建议阅读时自动将执行上下文理解成执行环境)。
变量或函数的上下文决定了他们可以访问哪些数据,以及他们的行为。
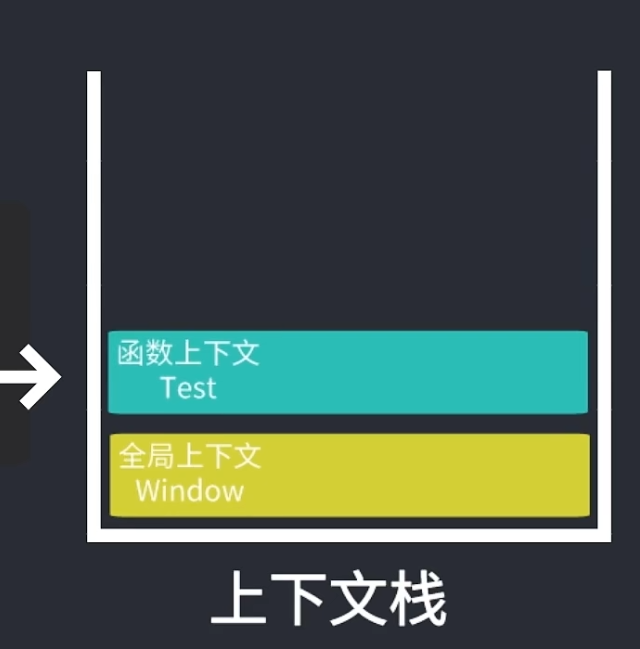
function Test() { console.log("Hello World!");}当代码执行流进入函数时,该函数的上下文被推倒上下文栈中,等到函数执行完之后,上下文栈会弹出该函数的上下文,将控制权返回给之前的上下文
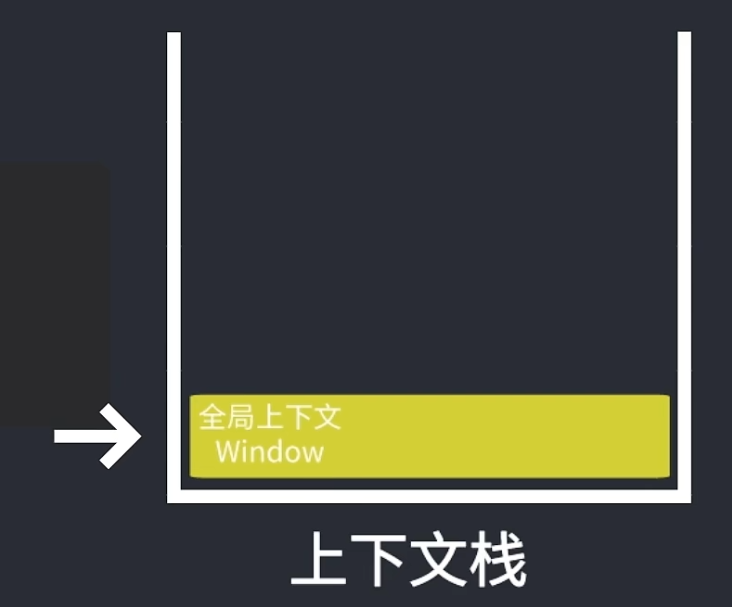
1.类型
全局执行上下文:最外围的执行环境,在浏览器情况下,在该环境的下执行的代码会执行以下步骤:(1)创建一个window对象;(2)将this指向这个window对象;通过var定义的全局变量和函数都会成为window对象的属性和方法。
函数执行上下文:每个函数都有自己的上下文,当代码执行到该函数时,函数的上下文被推到一个上下文栈上。在函数执行完后,上下文栈会弹出该函数的上下文,将控制权返还给之前的执行上下文。
2.生命周期
每个执行上下文的生命周期都经历了:创建 -> 执行 -> 回收 三个阶段
创建阶段:
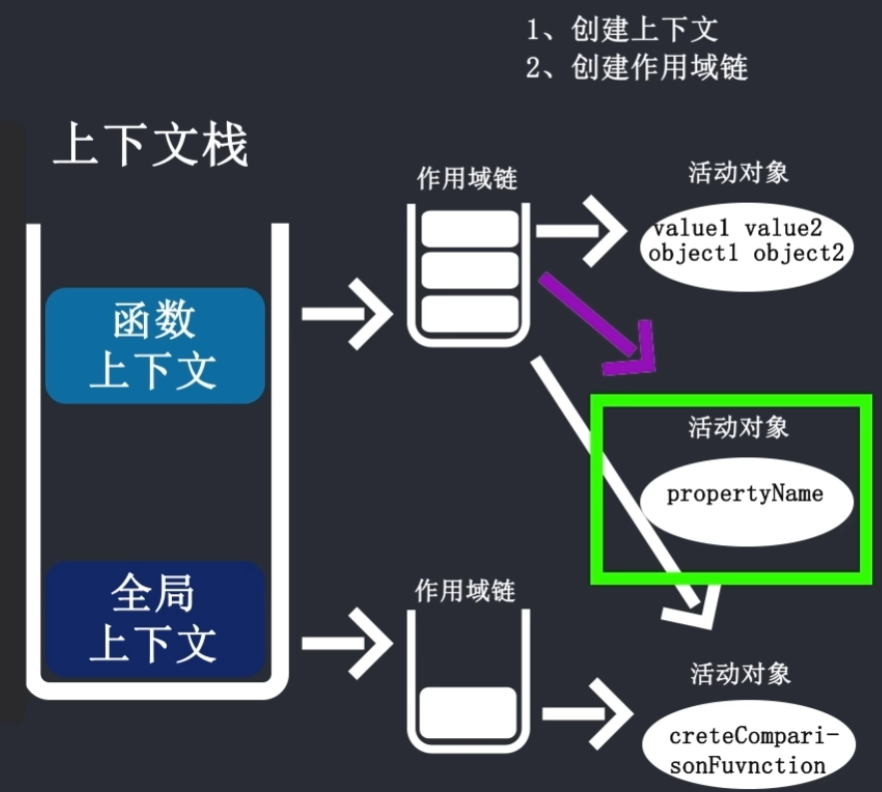
作用域链的创建
同时代码在执行栈中还伴随着作用域链的创建,作用域链决定了上下文中的代码访问变量的顺序以及权限
var color = "blue";function changeColor() { let anotherColor = "red"; function swapColors() { let tempColor = anotherColor; anotherColor = color; color = tempColor; } swapColors();}changeColor();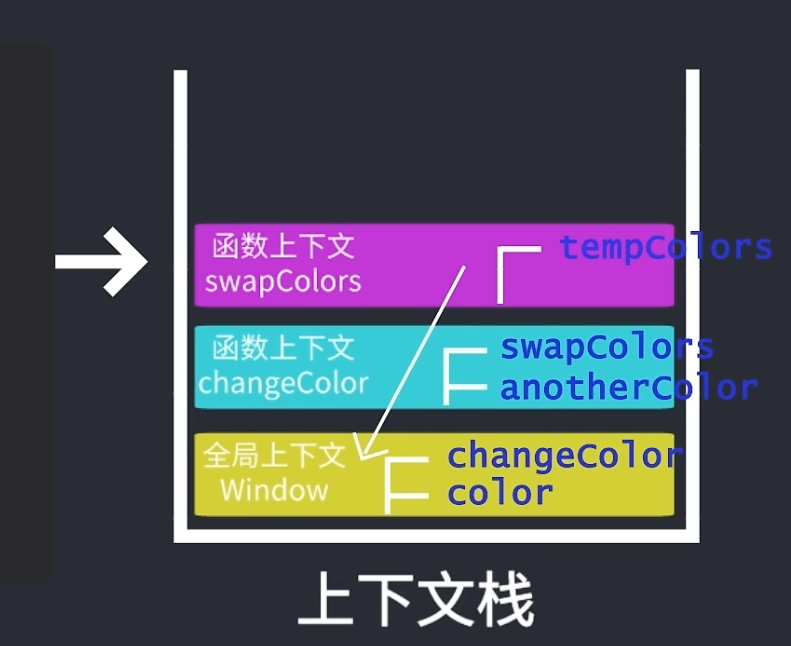
宿主环境是浏览器,那浏览器在代码执行之前就创建了一个全局上下文window,并将其推入上下文栈中,同时创建了一条作用域链
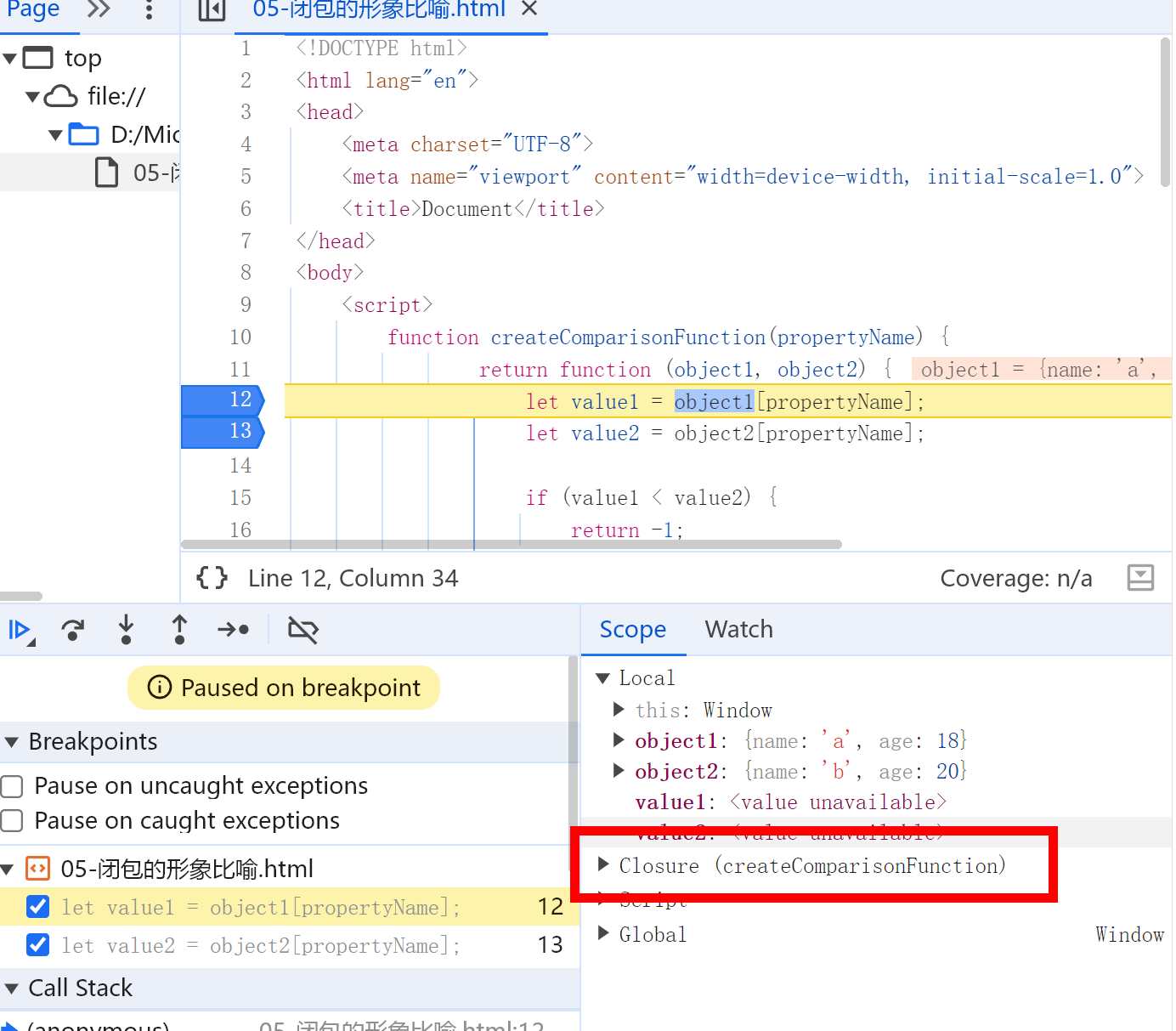
function createComparisonFunction(propertyName) { return function (object1, object2) { let value1 = object1[propertyName]; let value2 = object2[propertyName];
if (value1 < value2) { return -1; } else if (value1 > value2) { return 1; } else { return 0; } };}
let a = { name: "a", age: 18,};let b = { name: "b", age: 20,};
let compareAge = createComparisonFunction("age");let result = compareAge(a, b);
什么是闭包
闭包(closure)的概念
闭包代码举例:
function fun1() { const a = 10; return function fun2() { console.log(a); };}fun1();// fun1执行完毕,但a被fun2保留const result = fun1();// 在 fun1函数的外部,执行了内部函数 fun2,并访问到了fun1的内部变量aresult(); // 输出10 → 闭包生效全局作用域中,并没有定义变量a。正常情况下作为函数内的局部变量 a,无法被外部访问到。但是通过闭包,我们最后还是可以在全局作用域中拿到局部变量 a 的值。
注意,闭包函数是fun2,不是fun1。闭包的定义是:一个函数(fun2)与其周围状态(即词法环境,包含变量a)的组合。即使外部函数已执行完毕,内部函数仍能访问其作用域中的变量
闭包的表现形式
形式1:将一个函数作为另一个函数的返回值
function fn1() { var a = 2
function fn2() { a++ console.log(a) } return fn2}
var f = fn1(); //执行外部函数fn1,返回的是内部函数fn2f() // 3 //执行fn2f() // 4 //再次执行fn2当f()第二次执行的时候,a加1了,也就说明了:闭包里的数据没有消失,而是保存在了内存中。如果没有闭包,代码执行完倒数第三行后,变量a就消失了。
上面的代码中,虽然调用了内部函数两次,但是,闭包对象只创建了一个。
也就是说,要看闭包对象创建了几个,就看:外部函数执行了几次(与内部函数执行几次无关)。
形式2:将函数作为实参传递给另一个函数调用
在定时器、事件监听、Ajax 请求、Web Workers 或者任何异步中,只要使用了回调函数,实际上就是在使用闭包。
function showDelay(msg, time) { setTimeout(function() { //这个function是闭包,因为是嵌套的子函数,而且引用了外部函数的变量msg alert(msg) }, time)}showDelay('hello', 2000)上面的代码中,闭包是里面的function,因为它是嵌套的子函数,而且引用了外部函数的变量msg。
闭包的形象理解
//普通函数形式let count = 0;function fn() { count++; console.log(`函数被调用了${count}次`);}fn();
//闭包形式function outerFunction() { let count = 0; function innerFunction() { count++; console.log(count); } return innerFunction;}const counter = outerFunction();counter(); // 输出 1counter(); // 输出 2counter = null;你可以把闭包想象成一个带锁的保险箱:
outerFunction就像是一个制造保险箱的工厂。- 每次调用
outerFunction(),都会生产一个新的保险箱。 count变量就是放在保险箱里的贵重物品(比如金条)。innerFunction就是制作保险箱的流水线,作用域链就是钥匙const counter = outerFunction();这行代码,就是你给工厂派了一个订单,工厂给你了一个保险箱和金条(counter变量)。即使工厂(outerFunction)关门了,你仍旧有个保险箱,能够取出或修改里面的金条(count)。counter = null;这行代码,就像是你把钥匙扔进大海了。现在,世界上再也没有人能打开那个保险箱了。它和里面的金条就变成了无用之物,最终会被清洁工(垃圾回收器)清理掉。

闭包的形成条件和作用
(一)闭包的形成条件
- 嵌套函数:存在一个内部函数(闭包函数)嵌套在外部函数中。
- 变量引用:内部函数引用了外部函数作用域中的变量。
- 外部引用:外部函数执行后,内部函数被外部变量所引用,从而使得内部函数能够在外部函数作用域之外被调用。
(二)闭包的作用
- 封装变量:可以将变量封装在函数内部,形成私有变量,隔离作用域,避免变量被全局污染。例如,前面的计数器例子中,
count变量只能通过counter函数来操作,外部无法直接访问和修改。 - 延长变量生命周期:可以沿着作用域链查找,从而读取自身函数外部的变量,并让这些外部变量始终保存在内存中(延长了局部变量的生存周期),让函数创建时作用域内的变量,在函数执行结束后仍然能够被访问到,就像前面的
count变量。
闭包的应用
(一)积极影响
- 循环中绑定事件或执行异步代码
闭包能够保持函数内的状态,允许在函数调用之间保留和共享信息,这有助于实现一些需要记住状态的任务,比如计数器、缓存等。
// 使用闭包创建一个功能更完整的计数器function createCounter(initialValue = 0) { let count = initialValue; // 私有状态:计数变量
// 返回一个包含多个方法的对象 return { // 增加计数 increment: function (step = 1) { count += step; return count; },
// 获取当前计数值 getValue: function () { return count; },
// 重置计数 reset: function (newValue = initialValue) { count = newValue; return count; }, };}
// 1. 创建一个从 10 开始的计数器const myCounter = createCounter(10);
console.log(myCounter.increment());console.log(myCounter.increment(5));console.log("当前值:", myCounter.getValue());
myCounter.reset(); // 重置为初始值 10console.log("重置后:", myCounter.getValue());2.实现模块化
通过闭包可以创建具有私有变量和方法的模块,不同模块之间的变量不会相互干扰。例如:
const module = (function () { let privateVar = "私有变量"; function privateFunc() { console.log(privateVar); } return { publicFunc: function () { privateFunc(); }, };})();module.publicFunc(); // 输出 私有变量在这个模块中,privateVar 和 privateFunc 是私有成员,只能通过 publicFunc 来访问,实现了模块的封装性。
3.函数柯里化与偏应用
闭包是函数柯里化(将多参数函数转化为单参数函数序列)和偏应用(固定部分参数,生成新函数)的基础。比如:
function add(x) { return function (y) { return x + y; };}const add5 = add(5);console.log(add5(3)); //这里 add 函数返回的闭包记住了 x 的值,实现了函数的柯里化。
4. 面向事件编程
定时器、事件监听、Ajax 请求、跨窗口通信、Web Workers 或者任何异步,只要使用了回调函数,实际上就是在使用闭包
// 定时器function wait(message) { setTimeout(function timer() { console.log(message); }, 1000);}wait("Hello, closure!");// message 是 wait 函数的变量,但是被 timer 函数引用,就形成了闭包// 调用 wait 后,wait 函数压入调用栈,message 被赋值,并调用定时器任务,随后弹出,1000ms之后,回调函数timer 压入调用栈,因为引用 message,所以就能打印出 message
// 事件监听let a = 1;let btn = document.getElementById("btn");btn.addEventListener("click", function callback() { console.log(a);});// 变量 a 被 callback 函数引用,形成闭包// 事件监听和定时器一样,都属于把函数作为参数传递形成的闭包。addEventListener函数有两个参数,一为事件名,二为回调函数// 调用事件监听函数,将 addEventListener 压入调用栈,词法环境中有 click 和 callback 等变量,并因为 callback 为函数,并有作用域函数形成,引用 a 变量。之后弹出调用栈,当用户点击时,回调函数触发,callback 函数压入调用栈,a 沿着作用域链往上找,找到全局作用域中的变量 a,并打印出
// AJAXlet a = 1;fetch("/api").then(function callback() { console.log(a);});// 同事件监听只要是回调函数,函数中引入了变量,那就形成了闭包
可以说,在 JavaScript 中,所有函数都是天生闭包(除了 new Function 这个特例)
(二)消极影响
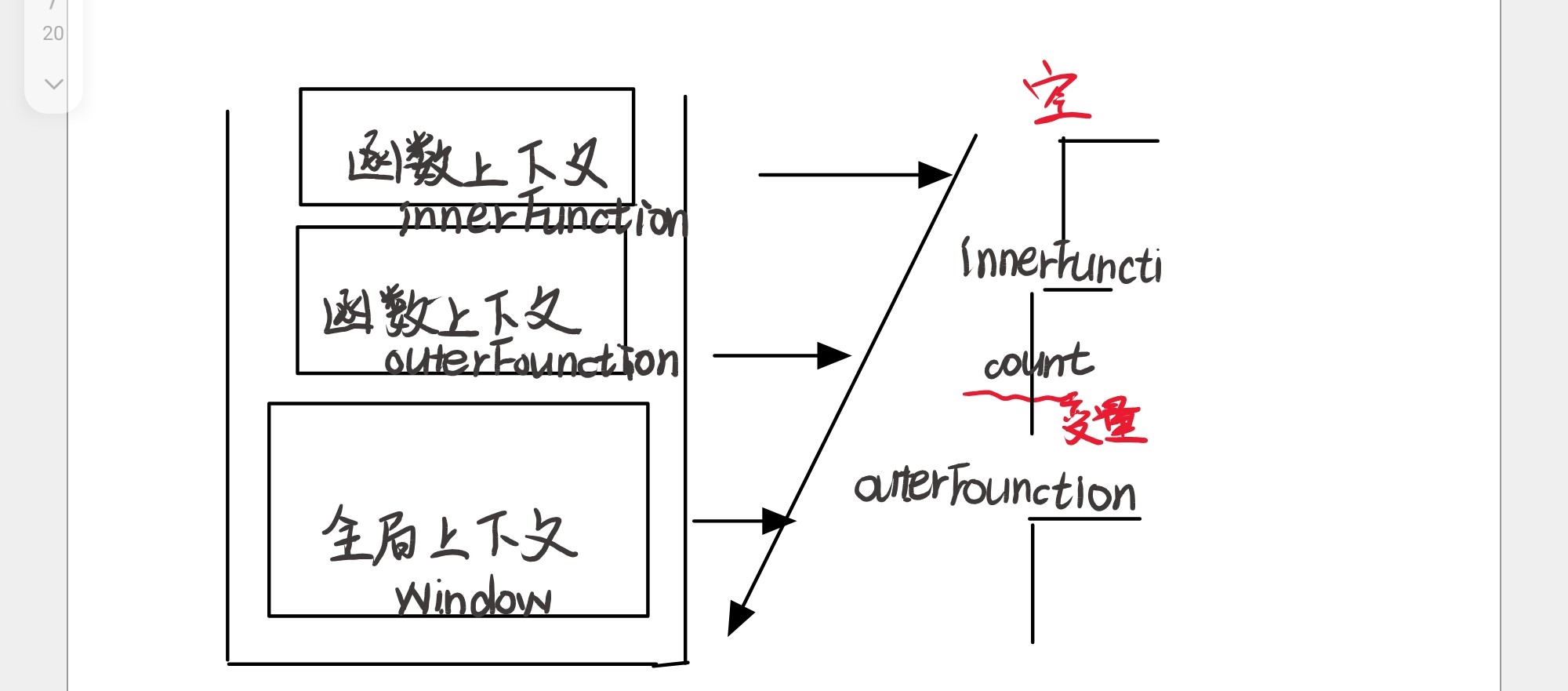
- 内存泄漏风险:因为闭包会保留对外部函数作用域的引用,导致外部函数作用域中的变量无法被垃圾回收机制回收,长期下去可能会造成内存泄漏。例如:
function outerFunction() { let count = 0; function innerFunction() { count++; console.log(count); } return innerFunction;}const counter = outerFunction();counter(); // 输出 1counter(); // 输出 2counter = null;谁会存在内存泄露?
count 变量
- conuter 是一个全局变量 ,代码执行完毕之后不会立即销毁
- counter使用outerFounction函数
- outerFounction 用到 innerFounction 函数
- innerFounction 函数里面用到count
- count被引用就不会被会回收所以一直存在
2. 性能影响:闭包的使用会涉及到作用域链的查找,相比直接访问局部变量,会有一定的性能开销。不过在大多数场景下,这种开销是可以接受的,但在对性能要求极高的应用中需要注意。
闭包是否会造成内存泄漏
一般来说,答案是否定的。因为内存泄漏是非预期情况,本来想回收,但实际没回收;而闭包是预期情况,一般不会造成内存泄漏。
但如果因代码质量不高,滥用闭包,也会造成内存泄漏。
总结
闭包是一种强大的编程机制,它让函数能够“记住”创建时的环境,为我们实现模块化、封装变量等提供了便利。但同时,我们也要注意闭包可能带来的内存泄漏和性能问题,在使用时合理规划,以充分发挥闭包的优势。
function addCount() { let count = 0; return function () { count = count + 1; console.log(count); };}
const fun1 = addCount();const fun2 = addCount();fun1();fun2();
fun1();fun2();打印结果:
1122代码解释:
(1)fun1 和 fun2 这两个闭包函数是互不影响的,因此第一次调用时,count变量都是0,最终各自都输出1。
(2)第二次调用时,由于闭包有记忆性,所以各自会在上一次的结果上再加1,因此输出2。
Some information may be outdated